




特斯拉视觉方案弊端初现,V2X+高精度地图才是自动驾驶的未来!

特斯拉引以为傲的Autopilot又出事了
近期,在中国台湾嘉义,一辆 Model 3 在高速公路上撞上了一辆侧翻的大货车。

事故发生在早晨 6 点 44 分,从视频可以看出,视频中出现的Model 3车辆在高速上行驶,看到前方有障碍物时车辆和驾驶员都没有采取制动或者换道避障,最终导致了车辆直直的撞了上去。
事后,据CNA报道,特斯拉车主向警方表示,事故发生时,车辆处于AutoPilot开启状态,时速定速在110公里。
他本以为,特斯拉侦测到障碍物会自动刹车。
所以,完全放心地把车辆的控制权,交给了特斯拉的高级辅助驾驶系统。
最后,当他发现前方有障碍物,Model 3却完全没有减速……等他想要接管——紧急踩下刹车时,事故已经没法儿避免。

对于这起事故很多人都好奇,特斯拉在自动辅助驾驶方面实力最强,但为什么没能自动识别正前方如此庞大的箱式大货车,反而还撞进了货箱箱体呢?
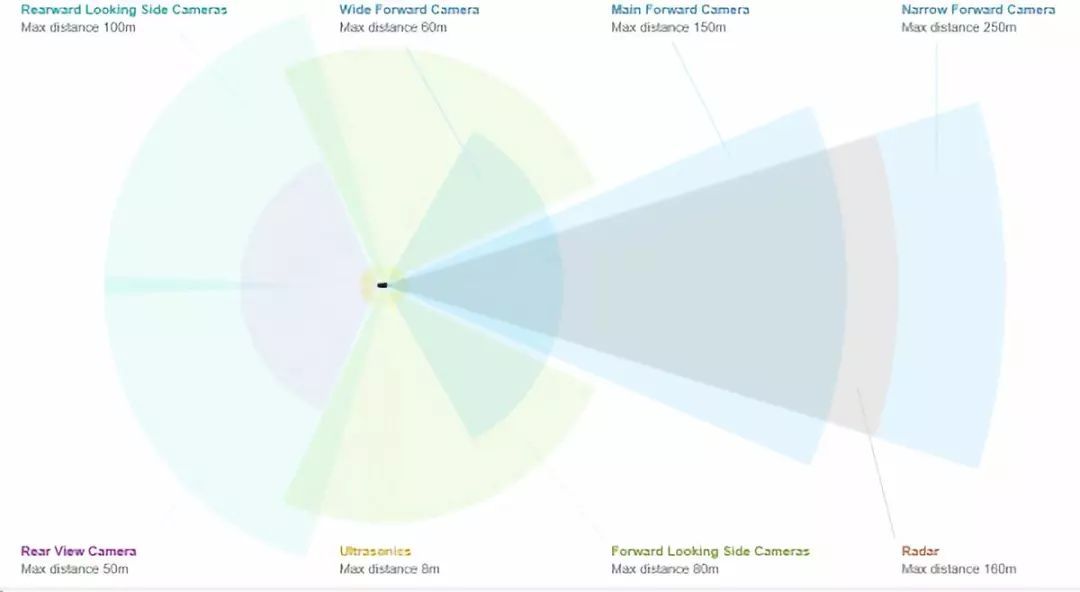
其实了解自动辅助驾驶感知原理的朋友都知道,特斯拉采用了视觉+毫米波雷达的感知方案。虽然前向有三个摄像头,兼顾车辆前方的宽视角以及远距离物体的探测,但不同焦距摄像头的物体识别方式与单目类似,基于深度学习模型,特斯拉叫它Tesla Vision。

其中主视野摄像头:范围可达150米,视野能覆盖大部分交通场景。
鱼眼镜头:视野120度,范围60米,能拍摄到交通信号灯、行驶路线上的障碍物和距离较近的物体,适用于城市街道、低速缓行的交通场景。
长焦距镜头:视野相对较窄,适用于高速行驶的交通场景,可以识别最远250米的物体。同时做行车记录仪使用。识别原理类似于单目,和双目RGB-D的原理不同。

而这种视觉且不是组合的传感器方案可能因为事故中的货车白色箱体有比较强烈的阳光反射,影响了这辆 Model 3 的摄像头识别。
除此之外就是视觉算法训练数据的局限性,一般自动驾驶视觉训练的都是识别车辆后部、侧面、车辆头部,工程师可能没想过有一天需要识别货车的箱体顶部。
可能有人会问,即使摄像头没有识别,车载的 77G 毫米波雷达也应该能识别障碍物。为什么毫米波雷达也没有起到作用?
其实,这套系统不是单独工作的,特斯拉采用的V1R (3 个摄像头+1 个毫米波雷达)的方案中,也就是三个前向摄像头加一个前项 77G 毫米波雷达的传感器方案。
在日常驾驶中,为了减少毫米波雷达对金属反射信号(例如井盖)而带来的 AEB 误触发,往往会用算法滤掉毫米波雷达对静态物体的信号,用摄像头识别多个目标,跟踪目标,同时用毫米波雷达对已识别物体进行检测和跟踪。
这一次摄像头显然未能识别目标,车辆的判断机制就很可能将雷达的信号当做误触发信号过滤掉了。
所以能够看出,特斯拉一直依赖的纯视觉+毫米波雷达的自动驾驶方案存在很大的局限性,在遇到很多没有训练过的场景时,系统很容易因为无法识别而失效。
写在最后:
事实上,在实现自动驾驶的道路上有很多种感知方案。其中特斯拉一直推崇纯视觉+毫米波雷达的感知方案。其优势是成本底,方便大规模商业化量产落地。但缺点大家也都看到了,如果出现的场景是系统未曾见过的,那大概率会撞上去。
除了特斯拉之外,其它的自动驾驶公司都非常注重安全。其中谷歌的Waymo采用了大量的激光雷达感知加高精度地图冗余方案;中国大部分自动驾驶公司的方案也更加倾向于激光+高精度地图+V2X。
这种方案的缺点是成本高,难商业化。但激光雷达感知受环境影响小、V2X可以实现超视距感知、高精度地图也可以做传感器的冗余备份,使得整套自动驾驶的感知方案安全性更高。
最后我认为,如果此次事故中的场景发生在采用了高精度地+激光雷达+V2X的自动驾驶车型上,大概率不会撞上去。而交通行业的底线就是保障驾乘人员的生命,所以自动驾驶的未来大概率是以V2X+高精度地图+激光雷达等融合而形成的高度可靠的自动驾驶系统。